Release 2.4
A63821-01
Library |
Product |
Contents |
Index |
| Oracle8
ConText Cartridge Application Developer's Guide
Release 2.4 A63821-01 |
|
![]()
![]()
This chapter describes the approach used by ConText to provide
thematic analysis of English-language text.
The following topics are covered in this chapter:
ConText linguistics is a system that extracts the main ideas
from English-language text and uses the main ideas to produce different
forms of output. These main ideas are referred to as themes.
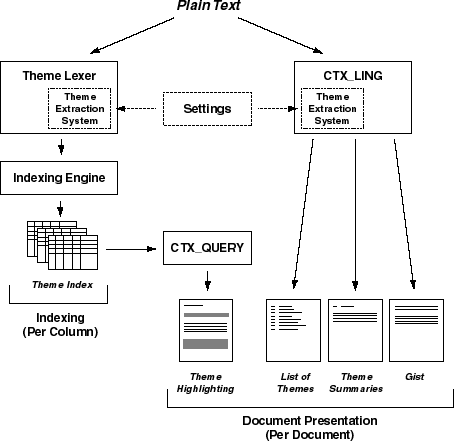
As shown in Figure 7-1, ConText's
theme extraction system extracts themes from documents to produce CTX_LING
output, theme highlighting, and theme indexes.
CTX_LING output is created on a per-document basis and gives
you different views of documents for presentation. Theme highlighting is
also available on a per-document basis. CTX_LING output and theme highlighting
are known as ConText document services.
Theme indexes are created from a document set, against which
you issue theme queries.
You can optionally use linguistic settings to control case
conversion of text before it is processed as well as to control the size
of Gists and theme summaries.
The theme extraction system illustrated in Figure
7-1 is comprised of a parsing engine and knowledge base which work
to extract themes from text. You can obtain thematic output in different
forms, depending on how you invoke the system. The following table describes
how to obtain each type of output:
| See
Also:
For more information about how the theme extraction system works, refer to the "Theme Extraction System" section in this chapter. For more information about theme summaries, list of themes, and Gists, see Chapter 8, "Using CTX_LING". For more information about theme highlighting, see Chapter 6, "Document Presentation: Highlighting". For information about creating theme indexes, see the Oracle8 ConText Cartridge Administrator's Guide.. For more information about issuing theme queries, see "Understanding Theme Queries" in Chapter 4. |
Themes are the main ideas in a document. Themes can be concrete
concepts such as Oracle Corporation, jazz music, football, England,
or Nelson Mandela; themes can be abstract concepts such as success,
happiness, motivation, or unification. Themes can also be groupings
commonly defined in the world, such as chemistry, botany, or
fruit.
When processing text to extract themes, Context extracts
up to fifty themes per document.
To derive document themes, ConText uses the information stored
in the knowledge catalog. Most themes are concepts in the knowledge catalog.
However, ConText can still infer themes that are not known concepts in
the knowledge catalog.
| See
Also:
For more information about the knowledge catalog and how ConText extracts themes, see "Theme Extraction System" in this chapter. |
ConText assigns a weight to every theme it extracts from
a document. Theme weight is a measure of how well that idea is developed
in the document with respect to other themes in the document.
ConText returns a theme weight with each theme returned in
a list of themes. During theme indexing, Context also indexes document
theme weights with themes and uses the weights to score theme queries issued
against the index.
Text input to the theme extraction system in Figure 7-1 can be one of the following:
The best results are obtained when the text input to the
theme extraction system is in mixed case. However, if your text is all-uppercase
or all-lower text, you can convert it to mixed case by changing linguistic
settings.
| See
Also:
For more information about linguistic settings, see"Linguistic Settings" in this chapter. |
In addition, having good paragraph and sentence structure
improves results for generating CTX_LING output, theme highlighting, and
theme indexes.
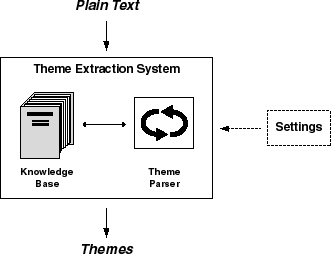
The theme extraction system extracts themes from English-language text. It is made up of the following components:
The knowledge base is a collective term referring to the
lexicon and the knowledge catalog. The parsing engine uses the knowledge
base to help extract themes from text.
The lexicon is a static information store that provides word
and phrase information for the parsing engine. The lexicon recognizes over
five hundred thousand English words and phrases and defines hundreds of
lexical characteristics for each word.
|
Note: The lexicon is specific to the English language, handling both American and British usage and spelling. |
Linguistic information about words in the lexicon is divided
into the following types:
In the theme extraction process, ConText uses the information
in the lexicon to identify potential themes, and to help rank themes in
a document.
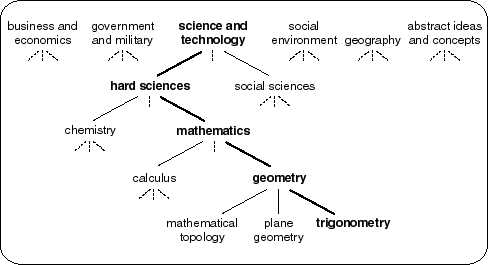
The knowledge catalog is a tree-like structure whose branches break down various realms of discourse. The knowledge catalog is divided into the following six main categories as shown in Figure 7-3:
| See
Also:
For a complete breakdown of the categories in the knowledge catalog, see Appendix E, "Knowledge Catalog - Category Hierarchy". |
Categories are groupings of related nouns and ideas that
can be sub-divided into further categories and concepts.
Children categories are related to parent categories by an
"is-associated-with" relationship, loosely defined as such to cover other
standard child-parent type relationships such as "is-a-part-of", "belongs-to",
or "is-a".
Figure 7-3 illustrates the basic
structure of the knowledge catalog, showing a break down of an example
branch within the top-level category of science and technology.
In the example branch (outlined in boldface), the category of trigonometry
belongs to the category of geometry, which is a part of the more
general category of mathematics, which is part of the even more
general category of hard sciences.
In the theme extraction process, ConText uses this structure
of categories and concepts to interpret document themes, to help relate
themes to each other, and to rank themes.
| See
Also:
For a complete listing of the categories in the knowledge catalog, see Appendix E, "Knowledge Catalog - Category Hierarchy". |
Concepts are leaf nodes in the knowledge catalog and can
be associated with any level in the category tree. Concepts are related
to parent categories by an "is-associated-with" relationship that covers
specific relationships such as "is-a".
The category of trigonometry, whose branch appears
in Figure 7-3, contains over 30 associated
concepts including sines, cosines, radians and polar
axes.
The category of success, located in the abstract
ideas and concepts branch, contains over 30 associated concepts including
award winners, conquerors, prosperity, and winning
streaks.
Concepts can be associated with any level in the category
tree. Using the example in Figure 7-3, the
category of mathematics, which is in the middle of the branch, has
over 130 associated concepts. Some of these concepts include Isaac Newton,
Fibonacci sequences, arithmetic progressions, and complex
integers.
Other categories such as flowering plants contain
over 1000 associated concepts.
The average number of concepts associated with a category
in the knowledge catalog is approximately 94.
In the theme extraction process, all concepts in the knowledge
catalog are potential document themes.
ConText's knowledge catalog is not an exhaustive repository
of all possible themes (concepts) that can be extracted from a document.
Some concepts that ConText might extract from a document are not known
to the knowledge catalog.
In addition, concepts such as bank, cricket,
or tangent can have more than one meaning in English and hence are
ambiguous. Because they are ambiguous, these concepts cannot be placed
in the knowledge catalog and are treated as if they are unknown.
| See
Also:
For more information about how ConText handles unknown and ambiguous themes in the theme extraction process, see the following sections: "Parsing Engine" in this chapter |
In the theme extraction process, ConText must convert words
and phrases in text to their normal forms so they can attach into the knowledge
hierarchy. To make this conversion, the knowledge catalog keeps the following
lists:
ConText uses the parsing engine to produce all types of thematic
output, including CTX_LING output and theme indexes.
The parsing engine syntactically analyzes text, identifying
phrase, sentence and paragraph boundaries. It then interprets meaning,
selecting the high-information content to produce themes. The lexicon and
knowledge catalog provide the reference information necessary to do this
processing.
If case-conversion is enabled, the parsing engine converts
all the text to lowercase and processes the text through the case-sensitivity
routines to determine capitalization.
|
Note: Case conversion does not affect the original text of the documents being processed; only the output of the parsing engine is stored in mixed-case. |
The following sections describe how the parsing engine analyzes
text to extract themes.
ConText breaks up text into paragraphs and then breaks paragraphs
into tokens. Tokens can consist of either single words or phrases. Words
are groups of characters separated by blank space or punctuation marks;
phrases are sequences of two or more words.
Information about English words and phrases is derived from
ConText's knowledge base. Sequences of words that match known phrases are
collapsed and treated as single tokens for further processing. For example,
the phrases stock market and relational database are treated
as tokens.
ConText converts each token to a normal form using information
stored in the knowledge base. Normal forms are the preferred forms of all
alternative forms of the token. When ConText is able to find the token
in the knowledge base it is a known token.
Specifically, token normalization includes the following
transformations of alternative forms to preferred forms: Verbs are converted
to their noun forms; most nouns are converted to their plural forms; and
acronyms and abbreviations are converted to their full forms. For example,
the acronyms IBM and I.B.M are converted to IBM - International
Business Machines.
Words that mean the same thing for the purposes of text indexing
and retrieval are also converted to normal forms. For example, the words
loving and amorousness are normalized to love.
When a token cannot be found in the knowledge base, ConText
guesses its part-of-speech and then normalizes it according to one of the
standard transformations. However, since the token cannot be placed in
the knowledge base, it is unknown, and is treated as its own normal
form isolated from the knowledge base.
In this step, ConText scores the normalized tokens, known
and unknown, then sorts the tokens, which are potential document themes,
into a ranked list. The scoring and ranking of tokens is based on the information
associated with each token in the knowledge base, such as what words and
parts-of-speech are good candidates for themes. The highest ranking tokens
are called themes.
ConText combines duplicated and closely related themes into
single themes. This is done by generalizing related themes to common parents
using the hierarchical structure of the knowledge catalog. The goal of
this process is to find the top-ranking themes, up to fifty, for a document.
In the final step, ConText looks back at the known themes
it generated and evaluates the evidence for each theme in the surrounding
text.
Because words can be ambiguous or can be used with new meaning,
ConText attempts to find support for the parent concept of each theme.
Parent concepts are derived from the knowledge catalog.
If no support exists for the parent concept, ConText indexes
the theme as a single row without the parent concept (theme).
Themes that are indexed as single rows have no parents in
the hierarchical list-of-themes you obtain with CTX_LING.REQUEST_THEMES.
| See
Also:
For more information about how ConText indexes themes, see "Theme Indexing Concepts" in Chapter 4. |
Linguistic setting are settings you can enable to control
how ConText processes text to extract themes.
There are two types of linguistic settings that affect output to the theme extraction system:
ConText provides two pre-defined linguistic setting labels
for case-conversion. These settings affect the processing of all text input
to the theme extraction system:
You can set linguistic settings labels with the CTX_LING.SET_SETTINGS_LABEL
procedure.
You can use the administration tool to create settings labels to control the following options:
When you use the administration tool to create your own settings,
you must use one of the ConText predefined settings as a starting point,
depending on whether your text is mixed-case, or all upper-case, or all
lower-case.
| See
Also:
For more information about using the administration tool to create your own labels, see the help file for the administration tool. For more information about Gists and theme summaries, see Chapter 7, "ConText Linguistics". |
To switch to a case-sensitive setting (SA) or to enable settings
labels you create with the administration tool, you must use the CTX_LING.SET_SETTINGS_LABEL
procedure.
|
Note: When you enable a setting other than the default, it affects the way ConText processes text for only that session. To obtain the same type of processing in a new session, you must re-enable the settings with CTX_LING.SET_SETTINGS_LABEL. |
| See
Also:
For more information on how to specify linguistic settings, see "Enabling Linguistic Settings" in Chapter 8, "Using CTX_LING". |