Computation and Data-Driven Discovery (C3D) Projects
Text Mining the Scientific Literature for X-ray Absorption Spectroscopy
Text mining is the process of automatically extracting meaningful information from large volumes of unstructured text data, information that can be directly presented to users or put into structured formats for populating databases. The National Synchrotron Light Source II (NSLS-II) at Brookhaven National Laboratory (BNL) is an emerging leader in x-ray spectroscopy with more than 25 beamlines in operation and additional ones under construction that enable scientific discoveries in clean and affordable energy, high-temperature superconductivity, and macromolecular crystallography. Users from academia and industry bring their samples to a beamline at NSLS-II for characterization of chemical bonding and electron energy band structure with the guidance of beamline scientists. During the short period of time users spend at the beamline for their experiments (typically several 4-hour sessions over 48 hours), they compare their sample spectra to those of well-characterized reference samples and adjust their measurement parameters. It is advantageous for users to quickly find comparable spectra from the scientific literature during the time they spend at the beamline. This is a complex information need as X-ray spectroscopy is a widely used method in many different disciplines, and traditional search engines return numerous irrelevant papers to sift through.
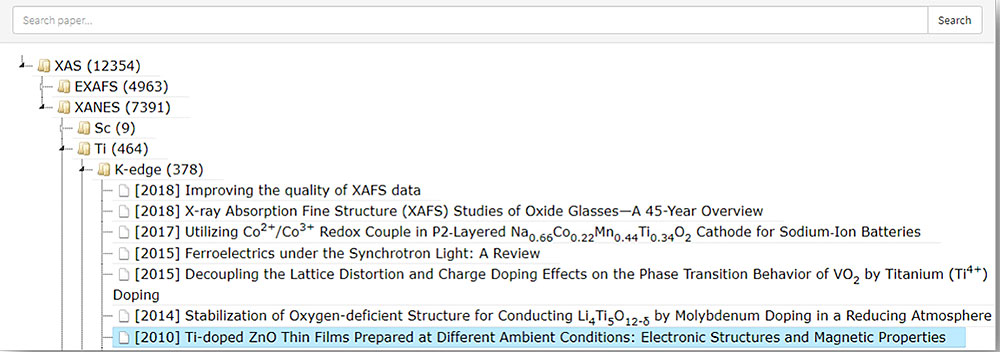
Figure 1: Classification of scientific articles in the TDM system.
We have designed a pilot system for Text and Data Mining (TDM) to provide direction for answering users’ complex information needs. The TDM system builds a data collection, extracts pertinent information from the scientific literature related to X-ray spectroscopy, and presents it to users in a Web portal. First, papers are classified according to 30 transition metals and their edges (K,L,M) (Figure 1). To perform the classification, figure captions have been analyzed using heuristic rules developed with the help of domain experts. The rules examine chemical elements, X-ray absorption spectroscopy (XAS) technique, and type of edge in the figure captions.
For papers chosen by a user, figures are extracted and presented with their captions (Figure 2). As captions often do not contain sufficient information and to minimize the amount of time beamline users spend reading through whole papers, explanatory text relevant to each figure is extracted from article text by a contextualized word embedding model and presented. The model compares figure captions with the body text of an article and finds the most similar sentences to present to users. A feedback button allows users to indicate how relevant these text snippets are to the presented figure and provides system developers with feedback to improve the system.
Figure 2: Extracted figure with its caption and explanatory text from the article body. (Image courtesy of Yong, Z., Liu, T., Uruga, T., Tanida, H., Qi, D., Rusydi, A., and Wee, A. T. (2010). Ti-doped ZnO thin films prepared at different ambient conditions: electronic structures and magnetic properties. Materials, 3(6), 3642-3653.
Publications
Park, G., Pouchard, L. “Scientific Literature Mining for Experiment Information in Materials Design.” Proceedings of the IEEE New York Scientific Data Summit (NYSDS), New York, NY, 2019. November 2019. DOI: 10.1109/NYSDS.2019.8909726.
Park, G., J. Rayz , and L. Pouchard, Figure Descriptive Text Extraction using Ontological Representation, 33rd International FLAIRS Conference, May 2020.
Gilchan Park, Line Pouchard, Advances in Scientific Literature Mining for Interpreting Materials Characterization. Machine Learning: Science and Technology (IOP Science) 2021 accepted.
Project Link (accessible with a BNL Guest appointment)