Brookhaven Lab Hosts Third GPU Hackathon
Participants from around the country and the world spent five days with graphics processing unit (GPU) programming experts to accelerate scientific applications spanning the fields of high-energy physics, astrophysics, chemistry, biology, machine learning, and geoscience
October 28, 2019
 enlarge
enlarge
The Computational Science Initiative at Brookhaven National Laboratory hosted its third graphics processing unit (GPU) hackathon from September 23–27, 2019. Some attendees were local or national, while others traveled all the way from Europe and Asia to participate.
Hardware devices called graphics processing units (GPUs) were originally developed for a specific purpose: to render images, animations, and video on computer screens. However, GPUs are also attractive for solving computationally intensive problems—such as those in science and engineering fields—because they can process large amounts of data at the same time, or in parallel. Recently, GPUs for general-purpose computing have emerged as new platforms for accelerating computations that would traditionally be handled by central processing units (CPUs).
Harnessing supercomputing power
Currently, the U.S. Department of Energy (DOE) has several large-scale computing systems based on general-purpose GPUs (GPGPUs), including Summit at the Oak Ridge Leadership Computing Facility (OLCF) and the upcoming Perlmutter at the National Energy Research Scientific Computing Center (NERSC)—DOE Office of Science User Facilities at Oak Ridge and Lawrence Berkeley National Laboratories, respectively—and Sierra at Lawrence Livermore National Lab. These supercomputers offer tremendous computing power for science and engineering applications, but software must be written to take full advantage of their GPGPU capabilities. Such programming requires a concerted effort among hardware developers, computer scientists, and domain scientists.
To facilitate such collaboration, the Computational Science Initiative (CSI) at DOE’s Brookhaven National Laboratory began hosting annual GPU hackathons three years ago. These CSI-hosted hackathons are part of the OLCF GPU hackathon series, which first began in 2014. Various institutions across the United States and abroad host hackathons throughout the year.
“It is great to see the energy in the room,” said hackathon organizing committee member and CSI computational scientist Meifeng Lin. “Everyone is completely absorbed in their codes, and there is a lot of interaction between the teams. This year, it has been interesting to see the teams who brought applications that have not traditionally run on GPUs or high-performance computing platforms—for example, machine learning (ML) and high-energy physics (HEP). Encouraging communities who are not used to working with GPUs is one of the goals of the hackathon series.”
This year’s hackathon was held from September 23 through 27 in partnership with Oak Ridge and the University of Delaware. Throughout the five-day coding workshop, GPU programming experts from Brookhaven, Lawrence Livermore, Oak Ridge, NVIDIA, Boston University, Columbia University, Stony Brook University (SBU), and University of Tennessee, Knoxville, worked side by side with nine teams comprising users of large hybrid CPU-GPU systems. The experts helped some teams with getting their scientific applications running on GPUs for the first time, and other teams with optimizing applications already running on GPUs. The teams’ applications spanned the fields of HEP (particle physics), astrophysics, chemistry, biology, ML, and geoscience.
A video capturing the hackathon experience and featuring interviews with some of the hackathon attendees.
Studying the building blocks of matter
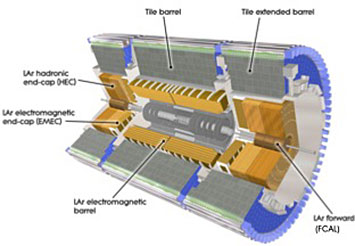
A cut-away view of the ATLAS calorimeter.
For example, Team FastCaloSim came to the hackathon with a code for simulating the ATLAS calorimeter. One of the largest particle physics experiments at CERN’s Large Hadron Collider (LHC) in Europe, ATLAS seeks to improve our understanding of the fundamental building blocks of matter and the forces that govern their interactions. The calorimeter is a detector that measures the energy of particles passing through. More than 1,000 particles fly through the detector after each collision, and all of them must be accurately simulated in order to reconstruct the event. Traditionally, such calorimeter simulations have been run on CPUs, taking a significant fraction of the total simulation time.
“We are now reaching the capacity of available computational power,” said CERN physicist Tadej Novak, one of the developers of the standalone FastCaloSim code. “Especially with the future upgrade of the LHC to a higher luminosity, we need to investigate new, modern methods to reduce the calorimeter simulation time while still getting accurate energies. By decoupling this code from the other ATLAS codes, we could learn how to make it run on GPUs more efficiently. We started with single particles of well-defined energies, and obtained comparable physics results between the CPU and GPU versions. The code was about three times faster on GPUs at the end of the week. Now we’re trying to run more realistic physics events and speed things up further.”
Hot QCD was another particle physics team. Quantum chromodynamics, or QCD, describes the theory of the force that holds together quarks and gluons—the elementary particles that make up protons, neutrons, and other particles.
“If you sit down at home, it would take months to achieve what we did in these five days with the help of our two mentors,” said Christian Schmidt, a senior researcher in the Theoretical High-Energy Physics Group at Bielefeld University in Germany.
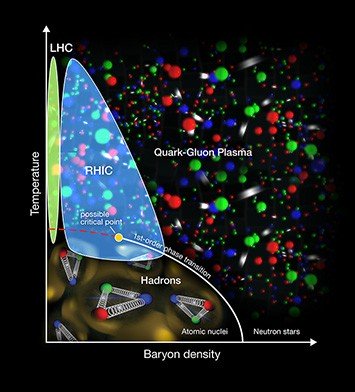
Quark-gluon plasma (QGP) phase diagram showing possible critical point in transition among different phases of nuclear matter.
Team Hot QCD’s code numerically simulates how elementary particles called quarks and gluons interact at very high temperatures and densities (plotting the interaction in a lattice with space and time on the axes). A quark-gluon plasma (QGP) was generated in the early universe seconds after the Big Bang, and today scientists recreate the QGP through collisions at the Relativistic Heavy Ion Collider (RHIC)—a DOE Office of Science User Facility at Brookhaven—and the LHC. Team Hot QCD’s code calculates thermodynamic properties of the QGP called conserved charge fluctuations. A comparison of these calculations with the experimental data can be used to probe the phase diagram of QCD matter.
“Scientists think a critical point may exist in the QCD phase diagram when the quark-gluon plasma “condensed” to form the protons and neutrons we are familiar with, similar to the liquid-vapor critical point of water,” said Schmidt. “But it is not clear from either simulations or experiments whether this point exists.”
The hackathon provided an opportunity for the team to explore QUDA, a library of algorithms for solving the lattice QCD physics equations on GPUs, with QUDA developers as their mentors.
“We hadn’t implemented these algorithms before,” said Schmidt. “In some cases, we saw an improved performance in our code; we were able to obtain more statistics with the same computing time. One of the challenges with the lattice QCD calculations is that there is a lot of noise, and collecting a higher number of statistics means we can calculate fluctuations of conserved charges more precisely.”
Discovering how the universe works
Three of the teams brought astrophysics codes: The ExaChoppers, AstroPUG, and Space.
The ExaChoppers brought a code that simulates how galaxies populate the universe, or where galaxies “live” in the universe. Their goal is to understand the statistical relationship between galaxies and the large-scale structure of the universe.
“Many observations of the sky boil down to counting the number of pairs of galaxies separated by some distance,” said Andrew Hearin, a member of the Cosmological Physics and Advanced Computing Group at Argonne National Lab. That’s the calculation we’re trying to do as fast as we can. A very large set of the applications run on CPUs, so we homed in on the most performance-critical bottleneck to optimize on GPUs. We achieved massive gains on the GPU algorithm we brought to the hackathon but we we’re still chasing after the industry-standard CPU implementation of this calculation. The GPU version could be roughly five to ten times faster.”
“We picked up a lot during the week that we will be able to apply for the next several months,” added Argonne cosmologist and computational scientist Matthew Becker. “For example, we learned how to take advantage of some features of the GPU structure by boiling down the problem into a very tiny kernel. Going forward, our work will be fleshing out that tiny kernel into a full-blown application.”
Team Space of the University of Michigan had two codes for simulating space plasmas, or ionized gases found throughout the universe: BATS-R-US, a hydrodynamics code which represents the plasma as a fluid; and AMPS, a particle-in-cell code which represents the plasma as a collection of particles. These codes are currently being used to forecast space weather events for the National Oceanic and Atmospheric Administration (NOAA) and to support National Aeronautics and Space Administration (NASA) missions. Space weather events are manifestations of how the Earth reacts to disruptive solar events (such as solar flares)—for example, geomagnetic storms, in which the Earth’s magnetic field has periodic disturbances. Understanding these events is important for a lot of systems we use on the Earth’s surface, such as global positioning systems (GPS), because data transmission can be affected.
“The challenge with coding for GPUs is that structurally you need to make sure that the code is designed for GPUs,” explained postdoctoral research fellow Qusai Al Shidi. “Converting CPU code into GPU code is not trivial because the essential differences in architecture mean the codes must be different as well.”
For BATS-R-US, the team managed to get a simplified version of their code—less than 1,000 lines of the original 150,000 lines—running on GPUs. Back at the University of Michigan, the team plans to apply the same ideas used to create this mini version of their code to port the complete one to GPUs. For AMPS, they had a similar approach of porting the particle-related calculation to GPUs first before tackling the entire code.
“This is my first GPU hackathon,” said Al Shidi. “I’m coming out of here with a lot of knowledge that I will use in the future.”
 enlarge
enlarge
X-ray bursts are thermonuclear explosions occurring near the surface of neutron stars. Team AstroPUG's "Maestro" astrophysics code simulates the dynamics of the convection leading up these bursts. Credit: Michael Zingale, SBU.
Team AstroPUG of SBU and Lawrence Berkeley came to the hackathon with an open-source suite of three codes for modeling different astrophysical events: stellar convective flows (how heat flows through stars), stellar explosions and mergers, and large-scale structure in the universe. By the end of the hackathon, Team AstroPUG had started running one of their main science problems on the Summit supercomputer on GPUs.
“Though we all work on different codes, we still collaborate because the codes share a lot of the same frameworks and physics solvers,” said Michael Zingale, an associate professor in SBU’s Department of Physics and Astronomy. “We’ve been to enough of these events now that we know what we need to do; it is just a lot of work. The hackathon setting provides a dedicated time where we can all sit together to focus.”
Understanding how dynamic structural changes impact biomolecule behavior
Team AlphaDog similarly knew what to expect, having participated in the 2018 GPU hackathon at Brookhaven.
“Last year, we worked on a code that is part of the molecular dynamics Amber software package,” explained Lauren Raguette, a graduate student in the Simmerling Group at SBU. “This year, we’re still working within Amber but on a completely different code. Instead of simulating proteins, this code simulates the interaction between water and proteins. Specifically, this code helps to model the nonpolar solvation energy.”
Solvation refers to the interaction between solvents and solutes, or dissolved molecules. Understanding how nonpolar biomolecules (i.e., those that do not easily dissolve in water) interact with water is important because these interactions play critical roles in the formation of biological structures—for example, cell membranes.
 enlarge
enlarge
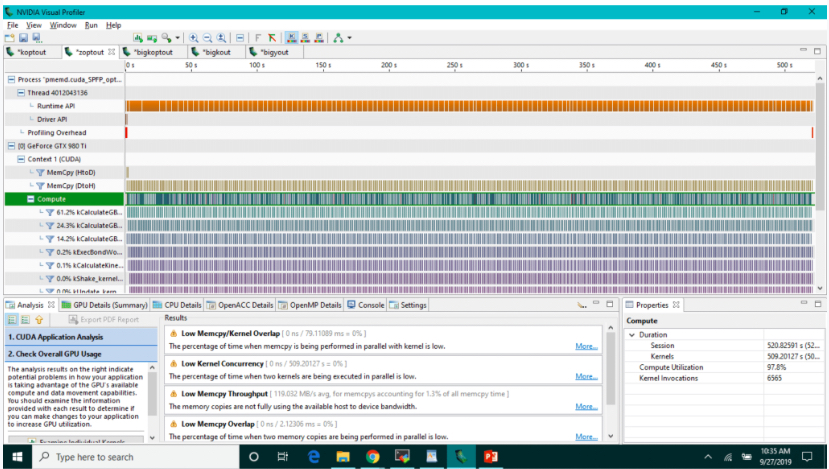
Team AlphaDog used a NVIDIA visual profiler tool to understand the performance of their code. A screenshot of the interface is shown above.
Compared to last year, the team’s progress was much more accelerated. They successfully ported their code onto GPUs by the second day instead of the last, giving them more time to spend with their mentors optimizing the computationally intensive parts of the code. For example, an analysis they ran with a performance profiling tool revealed that memory input and output was a bottleneck. By reducing the amount of memory access time, they were able to speed up their code.
Also new for this year, Team AlphaDog did not return alone—they brought the research group of professor Robert Rizzo of SBU’s Applied Mathematics & Statistics Department. This group is one of the core developers of DOCK, a widely used molecular docking program that helps researchers find and optimize the structures of small molecules in protein or nucleic acid receptor sites for drug design purposes.
Assessing risk for carbon dioxide sequestration sites
Scientists from Lawrence Livermore National Lab attended the hackathon to port a subsurface multiphysics reservoir simulator (GEOSX) to GPUs. This code is a component of the Subsurface: Exascale Subsurface Simulator of Coupled Flow, Transport, Reactions, and Mechanics, which is funded under the DOE Exascale Computing Project (ECP). Exascale computing refers to systems that can perform a billion billion calculations per second. The target problem for the GEOSX portion of this effort, which is a collaboration with Lawrence Berkeley National Lab and the National Energy Technology Laboratory, is modeling a wellbore failure in a carbon dioxide (CO2) storage site.
“Our goal is to understand the field-scale processes that impact the stability or viability of potential CO2 sequestration sites,” explained lead developer Randolph Settgast, a physicist at Lawrence Livermore. “Other applications of our code are focused efficient extraction of oil and gas resources, and geothermal energy production.”
At the hackathon, Team GEOSX worked on implementing three software libraries (RAJA, CHAI, and Umpire) to optimize features such as memory layout.
As one of the authors of RAJA, Thomas Scogland—a computer scientist at Lawrence Livermore—was the ideal resource to help the team with the optimizations. Scogland noted that he too benefits from the interactions:
“When it comes to programming models, people have a tendency to deal with any problems they encounter and not tell developers until these problems become serious,” said Scogland. “Being here, I can get direct feedback to see where things we have made are failing or where they don’t work as expected.”
Molecular modeling for chemistry research
Another ECP-related team was NWChemEx, the name of a next-generation computational chemistry tool targeting exascale computing architectures.
“NWChem enables you to probe the properties of molecular systems, such as energetics and structures,” explained CSI application architect Hubertus van Dam. “Initially, the code entirely ran on CPU. But we’re working on porting various components to GPU to prepare for exascale.”
Initially, the ECP project, called NWChemEx: Tackling Chemical, Materials and Biomolecular Challenges in the Exascale Era, will target advanced biofuel production as the science problem, with the goals of enhancing the nation’s energy security and minimizing climate change.
At the hackathon, the team specifically focused on the density functional theory (DFT) capability of the code. DFT is one of the most commonly used computational methods to calculate the electronic structure of atoms and molecules.
“There are about 500 density functional energy expressions,” explained David Williams-Young, a postdoctoral fellow in the Computational Research Division at Lawrence Berkeley. “One of our goals at the hackathon was to move the evaluation of these energy expressions to GPU to avoid communication with the host. For the DFT capability overall, we achieved a 10x speed up the protein called ubiquitin, which has 1,231 atoms and 10,241 basis functions. Now we have a pretty good idea of how to make further improvements through other optimizations.”
Scaling spatio-temporal machine learning algorithms
Machine learning has emerged as a powerful tool for efficiently analyzing large data sets collected over time and space, such as for climate and neuroscience studies. Team Model Parallelism for Spatio-Temporal Learning (MP-STL) and NERSC Extreme Science Applications Program (NESAP) Extreme-Scale STL (LSTNet) came to the hackathon with spatio-temporal deep learning algorithms to port and optimize on GPUs. Deep learning, a type of direct ML from raw data, is commonly used for classification tasks such as object detection.
 enlarge
enlarge
(Left to right) Graduate student Jaeyeong Yang of Seoul National University in Korea, CSI research associate Yihui (Ray) Ren, and CSI senior technology engineer Abid Malik explore the implementation of model parallelism for their deep learning code. Splitting the computations of a model across multiple devices would make the training of large machine learning models more practical.
“Our goal is to develop a model that can predict people’s fluid intelligence scores based on functional magnetic resonance imaging (fMRI) data obtained as tasks are completed by someone,” said Jaeyeong Yang, a graduate student in the Computational Clinical Science Laboratory at Seoul National University in Korea. “It is an open question in science whether this is possible or not. Currently, most image processing focuses on 2-D stationary images, such as photos of cats. The challenge in our case is that we have a large size of time-series 3-D fMRI images, more than 100 times larger than a regular photo.”
Yang and the other team members—who are focusing on whole genome sequence and brain segmentation data—will train scalable deep learning algorithms currently being developed by CSI computational scientist Shinjae Yoo. This genomics research leverages a GPU cluster at Brookhaven.
At the hackathon, Yoo and his collaborators from Brookhaven and NERSC explored using multiple GPUs at the same time to do ML-based multimodal analysis—particularly, combining different MRI brain imaging modalities with genetic data to study Alzheimer’s disease. They are using GPU nodes on Cori, an Intel Phi supercomputer at NERSC, for the multimodal brain imaging. The Alzheimer’s prediction code is the same as the one for fluid intelligence prediction but uses a different dataset and labels.
“This is a scalability challenge,” said Yoo. “By being able to analyze structural, diffusion, and functional MRI data in the context of genetic parameters, we expect better predictability of Alzheimer’s.”
CSI plans to host a fourth GPU hackathon at Brookhaven Lab, perhaps next summer.
The hackathon received support from DOE’s High-Energy Physics Center for Computational Excellence and the SOLLVE Exascale Computing Project, and was sponsored by Oak Ridge National Laboratory, NVIDIA, and OpenACC.
Brookhaven National Laboratory is supported by the U.S. Department of Energy’s Office of Science. The Office of Science is the single largest supporter of basic research in the physical sciences in the United States and is working to address some of the most pressing challenges of our time. For more information, visit https://energy.gov/science.
Follow @BrookhavenLab on Twitter or find us on Facebook.
2019-16729 | INT/EXT | Newsroom




