Defects in Magnetic Nanoparticles May Improve Cancer Treatment
X-ray studies reveal atomic-level distortions that enhance generation of heat for killing tumor cells or improving response to chemotherapy/radiation
February 20, 2020
 enlarge
enlarge
Brookhaven Lab scientists Ian Robinson, Milinda Abeykoon, and Emil Bozin at the XPD beamline at the National Synchrotron Light Source II (NSLS-II). The team used powerful x-rays to reveal how defects can improve nanoparticles' magnetic properties for use in treating cancer.
Scientists at the U.S. Department of Energy’s (DOE) Brookhaven National Laboratory have uncovered key details of magnetic nanoparticles that may improve their use in an innovative treatment known as magnetic hyperthermia—literally using magnets to turn up the heat on cancer.
Just a little bit of heat beyond physiological limits can kill a cancer cell, either directly or by making the cell more susceptible to the effects of radiation or chemotherapeutic drugs. The trick is getting the heat to only affect the tumor without killing the cells in the healthy tissue around it.
For about ten years, scientists have been exploring using magnetic nanoparticles, tiny crystals several thousand times smaller than a particle of dust, to generate heat directly in tumors. The idea is to inject a bunch of tiny magnetic particles into the tumor—or deliver them through the bloodstream tagged with tumor-seeking receptors—and then turn on an external magnet with an alternating magnetic field. Each time the tiny magnetic particles shift to align with the field, and then relax when the field turns off, they’ll release a bit of heat into the tumor.
“The goal for scientists is to identify the ideal parameters—the combination of magnetic field and particle properties—for dissipating heat with minimal disruption to the body,” said Brookhaven Lab physicist Emil Bozin.
One key characteristic is particle size: Particles larger than 20 nanometers (billionths of a meter in diameter) produce a bigger thermal response to magnetic field shifts, while particles smaller than 20 nanometers have somewhat inferior magnetic properties, Bozin said. But since “large” particles sometimes cause patient discomfort, scientists have been motivated to search for features that could improve the performance of the smaller particles.
 enlarge
enlarge
Alexandros Lappas, a chemical physicist and expert on magnetism, in his laboratory in Crete, Greece. He initiated this project while visiting Brookhaven National Laboratory as a Fulbright Scholar. (Credit: IESL-FORTH)
Brookhaven Lab scientists and a team of collaborators from Greece, Italy, and the United Kingdom did just that. They used powerful x-rays at Brookhaven’s National Synchrotron Light Source II (NSLS-II), a DOE Office of Science User Facility, to discover atomic-level defects that enhance the magnetic properties and heat-generating response of iron-oxide nanoparticles smaller than 20 nanometers. Their results, published in the journal Physical Review X, reveal that these performance-enhancing defects arise from “missing” iron atoms that cause the surrounding atomic structure to distort. The scientists noticed that the presence of iron vacancies in one location made adjacent vacancies more likely, and they found these defects in highest concentrations in the smallest, spherical nanoparticles.
“We have discovered a characteristic—defects caused by vacancies—that critically affects magnetic properties important for medical applications,” Bozin said. “If we can engineer those defects, we can use them to tailor the magnetic properties of iron-based nanoparticles to optimize their performance for magnetic hyperthermia cancer treatment.”
On the trail of tiny particles
The project originated with Alexandros Lappas, a chemical physicist and expert on magnetism leading the Quantum Materials and Magnetism Lab at the Institute of Electronic Structure & Laser, Foundation for Research and Technology Hellas (IESL-FORTH), Greece, who was visiting Brookhaven as a Fulbright Scholar. In his laboratory in Crete, Lappas synthesized a series of iron-oxide nanoparticles, cubes and spheres, all smaller than 20 nanometers. There were two sizes of each shape (we’ll call them small and smaller!).
“The goal was to study their atomic structure in the context of their observed magnetic properties,” Bozin said.
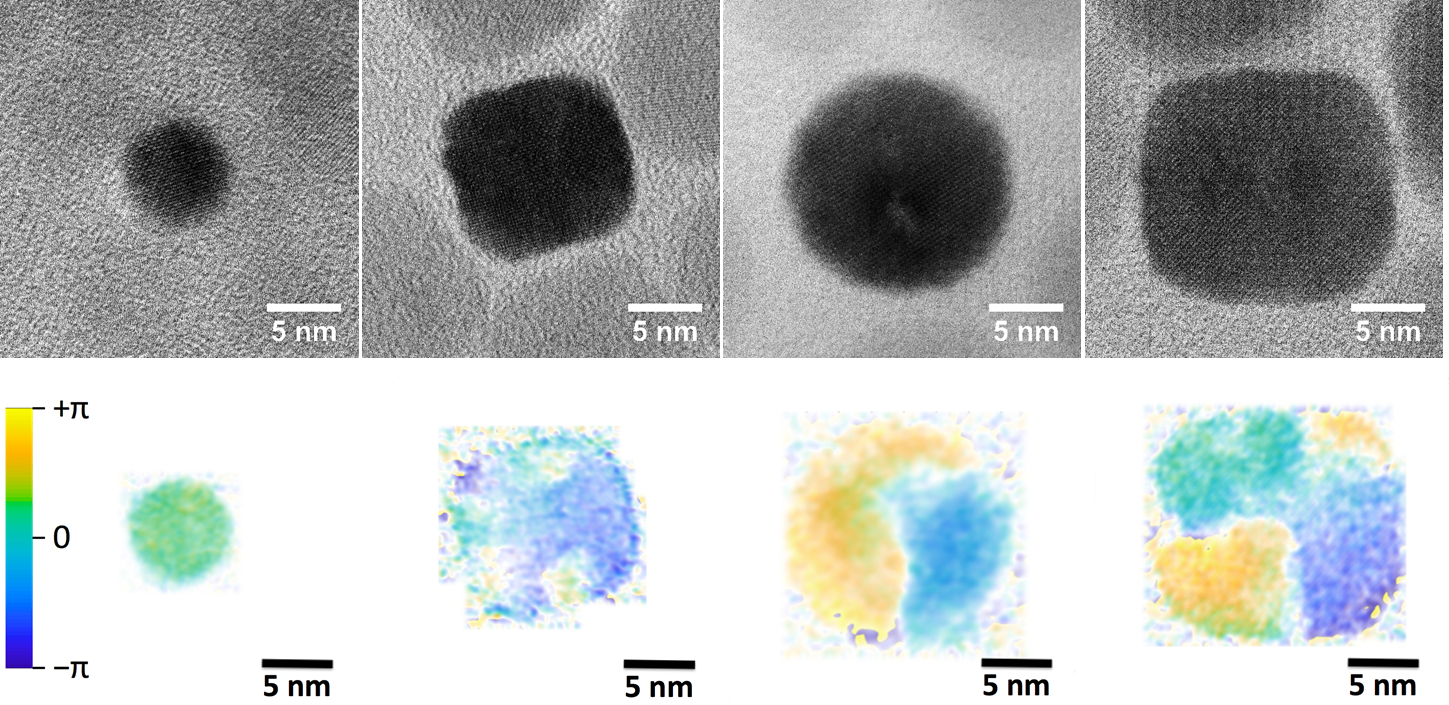
First the scientists created images of the full particles using a transmission electron microscope (TEM). Then they used mathematical techniques to translate each image into a “map” that allowed them to determine if the structure was uniform throughout or composed of different domains—for example, having one atomic arrangement at the core of the particle that differs from that of the exterior shell.
“The core and shell do not necessarily have the same structure or magnetic properties. And the interface between the two can be responsible for the heat-generating properties,” said Brookhaven Lab senior physicist Ian Robinson, a coauthor on the study.
 enlarge
enlarge
High resolution transmission electron microscope images of magnetic nanoparticles that were investigated in this work (top row). Multiple steps of mathematical transformation based on these images allowed scientists to map out the different domains and interfaces that may exist within these structures (bottom row). Understanding the magnetic properties within each domain and at interfaces between domains is an essential part of unraveling which properties would be optimal for applications such as magnetic hyperthermia.
The TEM images also provided clues about whether or not there were defects in the structure—which can manifest as stacking “faults” in the crystal.
“While it’s important to understand the influence of the shape and size of these particles on their magnetic properties, it is even more important to determine the role of the internal atomic structure within each domain,” Bozin said.
Since these particles are so small, conventional methods, such as x-ray crystallography, fail to reveal their atomic-level structures.
“Conventional crystallography works by using x-rays to pick out the broad-scale repeating pattern of atoms arranged in a crystal. When the arrangement of atoms is not periodic or when the crystal size becomes extremely small, as is the case with nanoparticles, the signals get smeared,” Bozin said.
Instead the team used an x-ray method that is sensitive to the atomic arrangement even in cases when there is no periodicity and when specimens take nanoscale form. This method, called x-ray total scattering-based pair distribution function (PDF), requires very high-energy x-ray beams such as those available at NSLS-II, specifically the X-ray Powder Diffraction (XPD) beamline.
“The higher the x-ray energy, the smaller the wavelength, and the smaller the features the x-ray beam can resolve, or ‘see,’” said Milinda Abeykoon, a beamline scientist at XPD and co-author on the study.
High-energy x-ray-vision
The scientists’ samples were powders containing millions of just one type of particle, placed in the beamline for analysis. When the x-rays scatter off the particles, they produce a diffraction pattern that can be translated into a kind of fingerprint mapping out the distances between pairs of atoms—pair distribution functions (PDFs). Computer models can then explore those PDFs to determine the most likely arrangements of the atoms, whether cubic or some other 3-D arrangement.
In the scientists’ analysis, there was one “peak” in the PDF signal that did not fit with any of the expected models.
“This suggested that at that specific atomic-pair location, the structure was not cubic, that it was some more complicated arrangement—a defect in the local structure,” Bozin said.
To figure out what was causing the defect, the scientists ran structural simulations where they varied the amount and location of iron atoms and compared those simulations to their experimental data. They were able to track down the “deficient PDF signal” to a deficiency in iron.
“There was some iron missing from one of the expected locations—like one empty chair at table for four,” Abeykoon said. “We discovered that the structure of these nanoparticles contains a relatively high concentration of such ‘iron vacancy’ defects.”
“The defects change the nanocrystals’ magnetic properties in the favorable direction,” said Lappas, the first author on the paper. “The iron vacancies act as ‘pinning’ centers that foster competition among the elementary magnets, in effect impeding their coherent reversal and easy relaxation in the alternating magnetic field,” he explained. “This allows a remarkable ten-fold rise of the nanomaterial's thermoresponsive performance, as compared to that obtained by defect-free entities.”
So maybe smaller particles can work for inducing magnetic hyperthermia.
The next step is to go back to the chemistry to learn how to make particles with the right kinds of defects reliably.
“How do we make the imperfections that we want? That’s a big challenge but also provides a bit of an opportunity, as determining the right chemical knob that can tune the synthesis of these particles in a favorable direction may produce the optimal kind of defects for this important biomedical application,” Lappas said.
The knowledge gained and methods used for this study could also have impact in a variety of fields that rely on understanding or manipulating magnetic properties at the nanoscale. These include data storage, sensors, and energy applications, as well as other medical uses such as contrast agents for computed tomography (CT) and magnetic resonance imaging (MRI), and magnetically driven drug-delivery methods.
The work was funded by the DOE Office of Science and, the Hellenic Republic National Strategic Reference Framework (NSRF) 2014-2020, and the U.S. Department of State Fulbright Visiting Scholar Program.
Brookhaven National Laboratory is supported by the U.S. Department of Energy’s Office of Science. The Office of Science is the single largest supporter of basic research in the physical sciences in the United States and is working to address some of the most pressing challenges of our time. For more information, visit https://www.energy.gov/science/
Follow @BrookhavenLab on Twitter or find us on Facebook
2020-17046 | INT/EXT | Newsroom




