Brookhaven Presents Big Data Pilot Projects at Supercomputing Conference
March 17, 2015
As the precision, energy, and output of scientific instruments such as particle colliders, light sources, and microscopes increases, so does the volume and complexity of data generated. Scientists confronting this high-tech version of “information overload” are faced with choices about which data to capture, share, and analyze to extract the pieces essential to new discoveries. High-performance computing (HPC) architectures have played an essential role in sorting the wheat from the chaff, with new strategies evolving to make optimal use of these resources and accelerate the pace of discovery in the world of ever-increasing data demands.
As part of a U.S. Department of Energy (DOE) effort to showcase new data-handling strategies, scientists from DOE’s Brookhaven National Laboratory demonstrated two pilot projects for modeling and processing large-volume data sets at the SC14 (Supercomputing 2014) conference held in New Orleans last November. The first project describes an effort to trickle small “grains” of data generated by the ATLAS experiment at the Large Hadron Collider (LHC) in Europe into small pockets of unused computing time, sandwiched between big jobs on high-performance supercomputers; the second illustrates how advances in computing and applied mathematics can improve the predictive value of models used to design new materials .
Granular Data Processing on HPCs Using an Event Service
 enlarge
enlarge
Brookhaven physicists Alexei Klimentov and Torre Wenaus have helped to design computational strategies for handling a torrent of data from the ATLAS experiment at the LHC, which produces one petabyte of raw data per second*, of potential interest to 3,000 scientists around the world.
Producing one petabyte of raw data per second*, of potential interest to 3,000 scientists around the world, the ATLAS experiment at the LHC is the epitome of a big-data challenge. Brookhaven physicist Torre Wenaus likens the search for interesting “events”—collisions between particles that might yield significant discoveries—to searching for a single drop of water in the 500-liter-per-second spray from Geneva’s Jet d’Eau fountain over the course of more than two days.
“Distilling the physics from this torrent of data requires the largest distributed data intensive scientific computing infrastructure ever built,” Wenaus said. With the LHC getting ready to come online this year at nearly twice the collision energy of its previous run, the torrent and data-handling needs are about to expand exponentially. Wenaus and others have been working to ensure that computing capabilities are up to speed to gain access to new insights into the Higgs boson and other physics mysteries, including the search for exotic dark matter particles, signs of supersymmetry, and details of quark-gluon plasma that the torrent of data might reveal.
According to Wenaus, the key to successfully managing ATLAS data to date has been highly efficient distributed data handling over powerful networks, minimal disk storage demands, minimal operational load, and constant innovation. “We strive to send only the data we need, only where we need it,” he said.
“Thanks to hard work and perseverance, we’ll be ready when the new torrent of data begins to flow.”
— Brookhaven/ATLAS physicist Torre Wenaus
“We put the data we want to keep permanently on tape or disk—about 160 petabytes so far with another 40 petabytes expected in 2015—and use a workload distribution system known as PanDA to coherently aggregate that data and make it available to thousands of scientists via a globally distributed computing network at 140 heterogeneous facilities around the world.” The system works similar to the web, where end users can access the needed files, stored on a server in the cloud, by making service requests. “The distributed resources are seamlessly integrated, there’s automation and error handling that improves the user experience, and all users have access to the same resources worldwide through a single submission system.”
 enlarge
enlarge
Torre Wenaus likens the search for interesting collision events at ATLAS to searching for a single drop of water in the 500-liter-per-second spray from Geneva's Jet d'Eau fountain over the course of more than two days. "Jet-d'eau-Genève" by Michel Bobillier aka athos99 - Photo prise par Michel Bobillier aka athos99. Licensed under CC BY 2.5 via Wikimedia Commons
The latest drive, and subject of the SC14 demo, is to move the tools of PanDA and the handling of high-energy physics data to the realm of supercomputers.
“In the past, high-performance supercomputers have played a very big role on the theoretical side of high-energy physics, but not as much in handling experimental data,” Wenaus said. “This is no longer true. HPCs can enrich our science.”
The challenge is that time on advanced supercomputers is limited, and expensive. “But just as there’s room for sand in a ‘full’ jar of rocks, there’s room on supercomputers between the big jobs for fine-grained processing of high-energy physics data,” Wenaus said.
The new fine-grained data processing system, called Yoda, is a specialization of an “event service” workflow engine designed for the efficient exploitation of distributed and architecturally diverse computing resources. To minimize the use of costly storage, data flows would make use of cloud data repositories with no pre-staging requirements. The supercomputer would send “event requests” to the cloud for small-batch subsets of data required for a particular analysis every few minutes. This pre-fetched data would then be available for analysis on any unused supercomputing capacity—the grains of sand fitting in between the larger computational problems being handled by the machine.
“We get kicked out by large jobs,” Wenaus said, “but you can harvest a lot of computing time this way.”
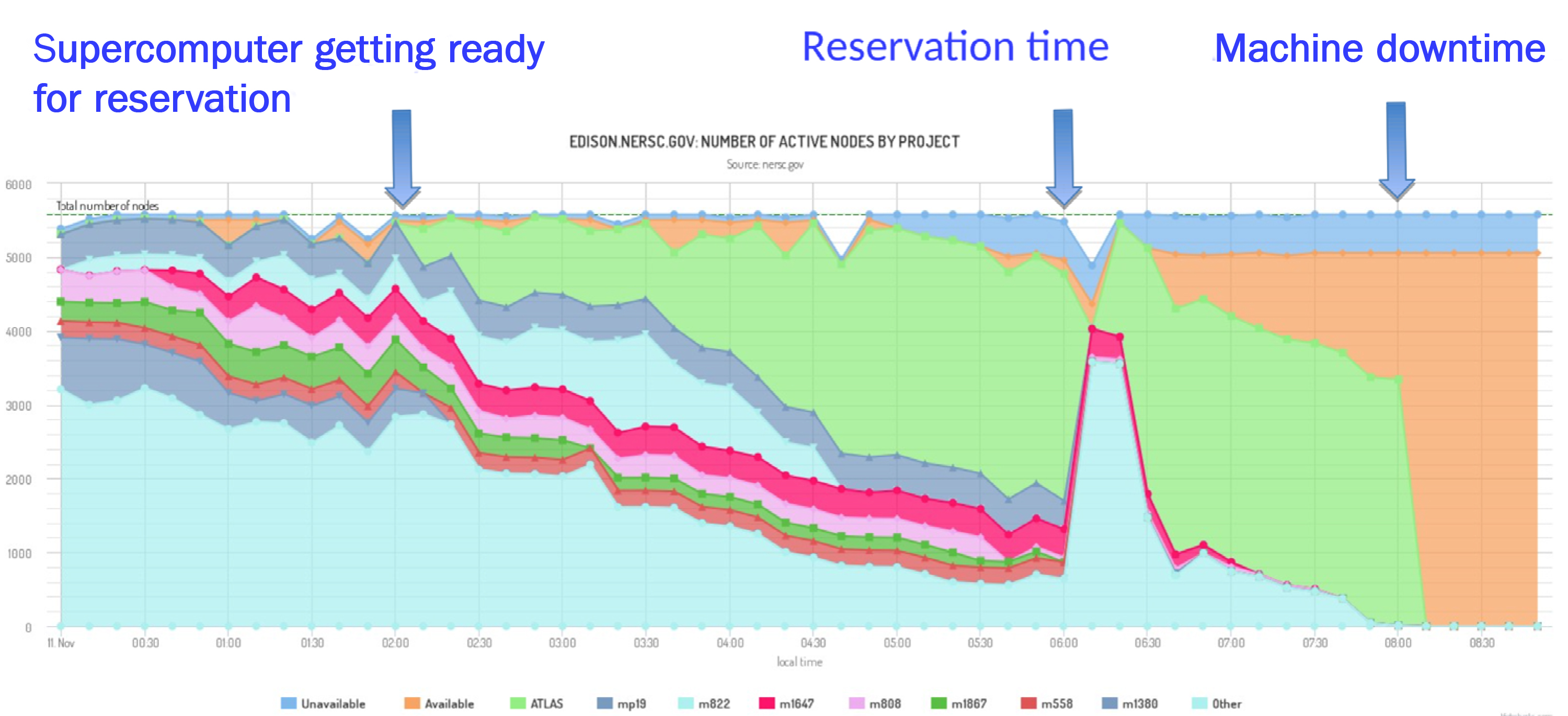 enlarge
enlarge
In a test, the ATLAS team demonstrated how they could make use of a large amount of unused computation time by submitting a bunch of physics simulation jobs (light green portion of graph) into the "killable queue" of a supercomputer prior to a scheduled maintenance time or before a large job reservation.
This system was constructed by a broad collaboration of U.S.-based ATLAS scientists at Brookhaven Lab, Lawrence Berkeley National Laboratory, Argonne National Laboratory, University of Texas at Arlington, and Oak Ridge National Laboratory, leveraging support from the DOE Office of Science—including the Office of Advanced Scientific Computing Research (ASCR ) and the Office of High-Energy Physics (HEP)—and the powerful high-speed networks of DOE’s Energy Sciences Network (ESnet).
With the demo a success, the next step is to use this approach for real ATLAS data analysis. That will require a push for further improvements in moving data efficiently across the networked computers, which the physicists are working on now.
The LHC is set to start colliding protons at unprecedented energies by this May with the physics program going full swing by mid-summer. “Thanks to hard work and perseverance,” said Wenaus, “we’ll be ready when the new torrent of data begins to flow.”
Brookhaven Lab’s participation in the ATLAS experiment is funded by the DOE Office of Science.
Brookhaven National Laboratory is supported by the Office of Science of the U.S. Department of Energy. The Office of Science is the single largest supporter of basic research in the physical sciences in the United States, and is working to address some of the most pressing challenges of our time. For more information, please visit science.energy.gov.
*One petabyte per second comes off the detector—the events that pass through the fastest and least restrictive trigger—but this data set is filtered down by more detailed selection algorithms that are part of the experiment so that only a few gigabytes per second of the most interesting events are actually recorded and analyzed.
2015-5571 | INT/EXT | Newsroom




