Computation and Data-Driven Discovery
CODAR: Co-design Center Online Data Analysis and Reduction at the Exascale
By 2024, computers are expected to compute at 1018 operations per second but write to disk only at 1012 bytes per second—a compute-to-output ratio 200 times worse than on the first petascale systems. In this new world, applications must increasingly perform online data analysis and reduction, which are tasks that introduce algorithmic, implementation, and programming model challenges unfamiliar to many scientists with significant implications for the design of various exascale system elements.
The Co-design Center for Online Data Analysis and Reduction at the Exascale, or CODAR, aims to produce infrastructure for online data analysis and reduction (Cheetah/Savanna); import, integrate, and develop essential libraries by using this infrastructure (FTK, MGARD); incorporate these libraries into scientific applications and quantify accuracy (Z-checker) and performance (Chimbuko); release software artifacts; construct application-oriented case studies; document success stories and the process applied to obtain them; and report on codesign trade-off investigations.
CSI’s role in this project is the development of Chimbuko, the first online performance analysis tool for exascale applications and workflows. The Chimbuko framework captures, analyzes, and visualizes performance metrics for complex scientific workflows and relates these metrics to the context of their execution (provenance) on extreme-scale machines. Chimbuko enables empirical studies of performance analysis for a software or workflow during a development phase or in different computational environments.
Chimbuko affords the comparison of different runs at high and low levels of metric granularity by capturing and displaying aggregate statistics, such as function profiles and counter averages, as well as maintaining detailed trace information. Because trace data can quickly escalate in volume for applications running on multi-node machines, Chimbuko’s core is an in situ data reduction component that captures trace data from a running application instance (e.g., MPI rank) and applies machine learning to filter out anomalous function executions. By focusing primarily on performance anomalies, a significant reduction in data volume is achieved while maintaining detailed information regarding those events that impact the application performance.
Along with providing a framework to allow for offline analysis of the data collected over the run, Chimbuko also provides an online visualization tool where aggregated statistics and individual anomalous executions can be monitored in real time.
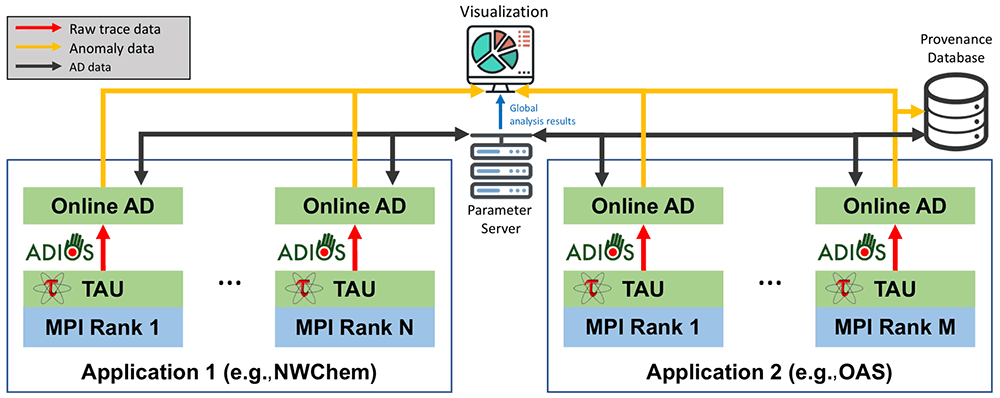
Basic layout of the Chimbuko framework
- The ADIOS framework orchestrates workflow and provides data streaming.
- The TAU tool provides performance metrics for instrumented components in Applications 1 and 2 (see figure). The tool extracts provenance metadata and trace data.
- Trace data are dynamically analyzed to detect anomalies by the Online AD modules, and aggregate statistics are maintained on the parameter server.
- Detailed provenance information regarding the detected anomalies is stored in the provenance database, an UnQLite JSON document-store remote database provided by the Mochi Sonata framework.
- The visualization module allows for interaction with Chimbuko in real time.